Language-Image model
Language-Image model
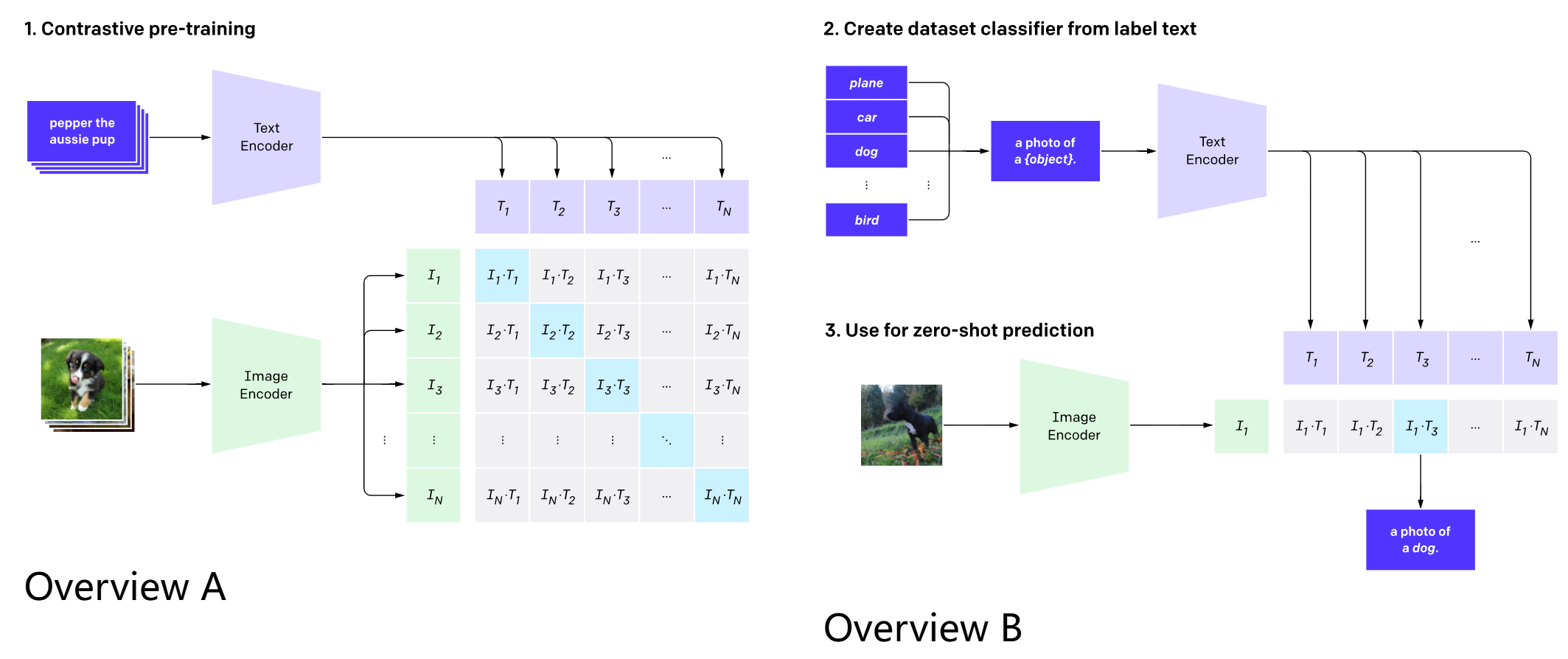
CLIP(Contrastive Language-Image Pre-train)
2021.01
text encoder + image encoder -> 类似 transformer 中的 Q* K
Virtex ?
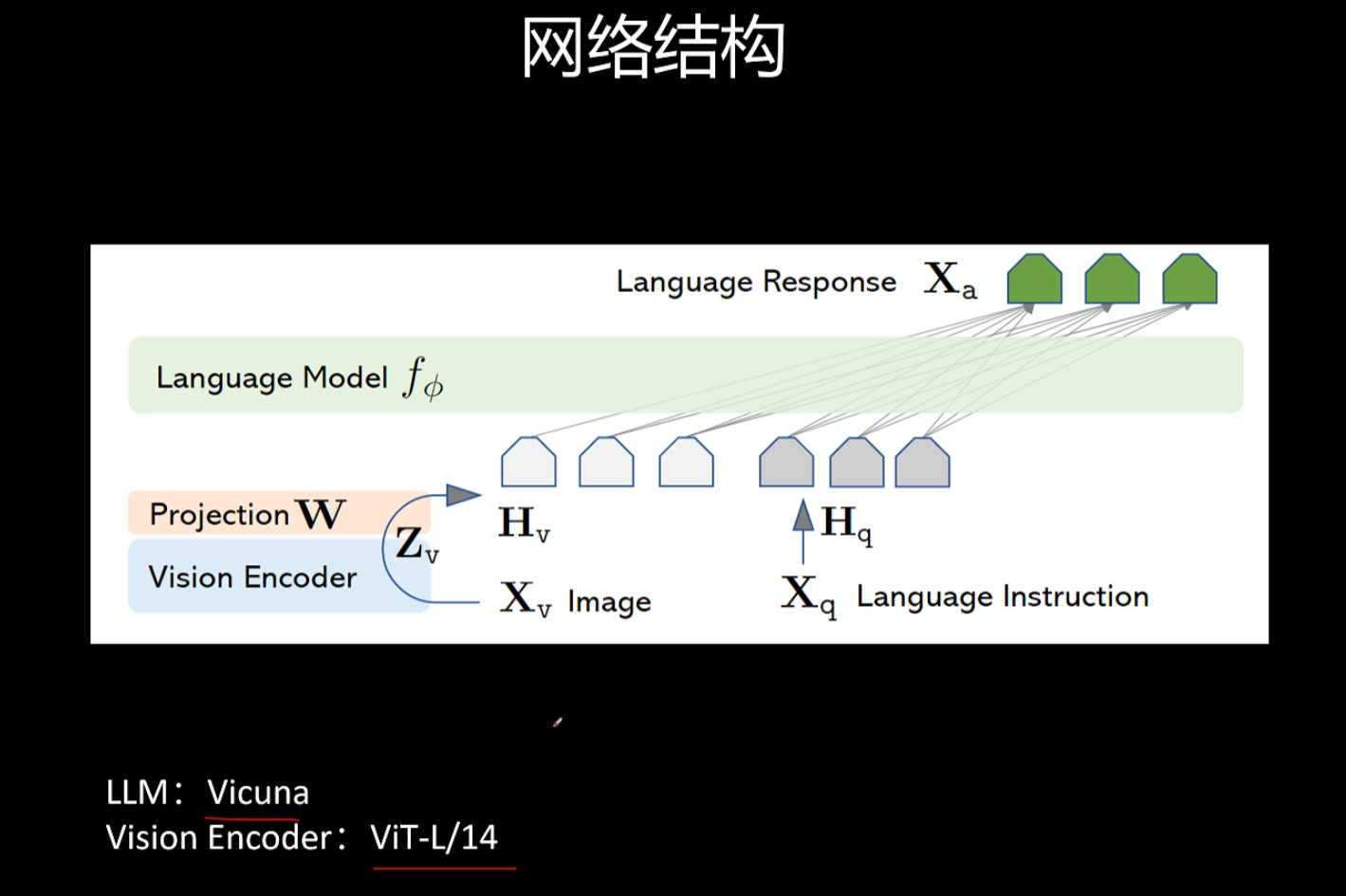
Llava

This post is licensed under CC BY 4.0 by the author.
2021.01
text encoder + image encoder -> 类似 transformer 中的 Q* K
Virtex ?